

Building Relationships.

Our world is built on relationships. We work with colleagues, clients and vendors; even a hermit needs plants and animals for food. Life itself is formed through a complex series of connections.
The same is true with data we collect and generate. Sometimes we want to connect clients with projects, other times with invoices and payments. Having a system with the flexibility to do both is critical, otherwise we are plagued by needless duplication and the errors that inevitably result. That is why relational databases are so useful.
Structure is Everything. Probably nothing is more frustrating to a data analyst than finding that we cannot get the answers we want even though all the necessary information is in the computer. For example, we can’t analyze client data by state if the database doesn’t have a way to separate the state from the rest of the client’s address. Typically this would be done by storing the state in a separate “field.” Deciding how to divide information into fields and records is a critical step in designing a useful database and is discussed in Organizing Data for Analysis.

Deciding on an optimal field and record structure becomes more complicated when a database is used for multiple purposes. For example, a payroll system needs to track gross pay and tax withholding by employee when cutting checks so it can pay each person the correct amount. But when computing how much tax money to send to the government, the system needs to connect deductions to pay period and tax type. The system might also be used to track insurance, vacation and other benefits, each of which would require yet additional types of connections.
Eventually it becomes impractical to put so much unrelated information into a single set of fields and records, called a table. For example some benefits may only be available to certain individuals. Giving every person’s record a separate field for every possible item would make the system unwieldy.
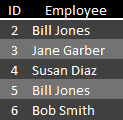
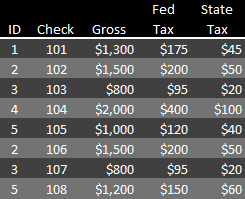
Breaking Things Apart. The solution is to break the database into several tables and connect them when appropriate. For example, a simple payroll database can have two tables, one with a record for every person (See Fig. 1), another with a record for every paycheck (See Fig. 2). Each table is perfectly functional on its own, for example the employee table by itself has everything necessary to create a company directory, but they can be used together to combine names and dollars on paychecks.
Putting Them Back Together. To connect tables there must be some common identifying information in both, employee ID in our example. Usually the linking field is unique on one side of the relationship, like ID is in our employee table. That’s how the system makes sure each person gets the correct paycheck even where several people have the same name. We have two Bill Joneses, perhaps a father and son, but they are linked to their checks by different IDs so each gets paid correctly.
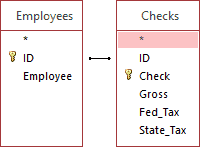
Building a relationship typically involves telling the system what the common fields are in both tables, for us it is ID. Our system uses the same field name in both tables, but it wouldn’t have to. Figure 3 shows how our relationship would be built in a Microsoft Access query. Most relational databases are based on SQL (Structured Query Language) and sometimes you write SQL code to build relationships.

Once the relationship is established, the database can use information from both tables together. Thus in our payroll system, employee names can be combined with pay and withholding data. If we had other tables for employee vacations, benefits and sick days, they could be linked to the people’s names as well.
Relationship Types. Our sample relationship is sometimes referred to as one-to-many since every employee can have an unlimited number of paychecks, but each paycheck can only have one employee. This is the most common type, although there are one-to-one and many-to-many relationships.
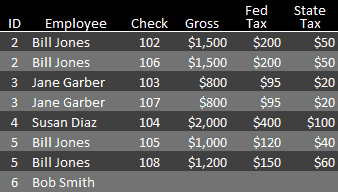
The list in Figure 4 only includes records for IDs that have at least one entry in each table. For example, Figure 2 contains a Check 101, but it is not in the combined list since its payee, ID 1, is not in the employee table, perhaps because he retired. Nor is Bob Smith, ID 6, in the combined list since he hasn’t yet been issued a check. In SQL this type of relationship is called an Inner Join.
We can also create a relationship that lists every employee and leaves the check data blank if there are none (See Fig. 5), or vice versa. These are called Left and Right Joins.
Benefits of Relational Databases. Just like dividing data into fields lets us use the state portion of an address separately from the rest when appropriate, and combine it with city and ZIP code when that is helpful, putting information in related tables gives us the flexibility to combine related items in different ways for different purposes. One-to-many relationships also make it easy to handle situations where some people have more transactions than others. For example, simple fundraising systems sometimes have one record for each donor and a field for each year's campaign — unfortunately that system cannot accomodate someone who wants to make an extra contribution one year.
* * * * *
“No man [or woman] is an island.”1 So it is with data as well — few pieces of information are useful except as part of a larger picture. Relational databases give us the flexibility to join items in different ways to provide a variety of useful combinations.
-----
- From John Donne, Devotions upon Emergent Occasions (1624).
This article originally appeared in our free semi-monthly newsletter. To receive future issues, please add your name to the subscription list.